
Workflow-GYM: Towards Long-Horizon Evaluation of Computer-use Agentic tasks in Real-World Professional Fields
1ByteDance Seed, 2M-A-P, 3Humanlaya AI
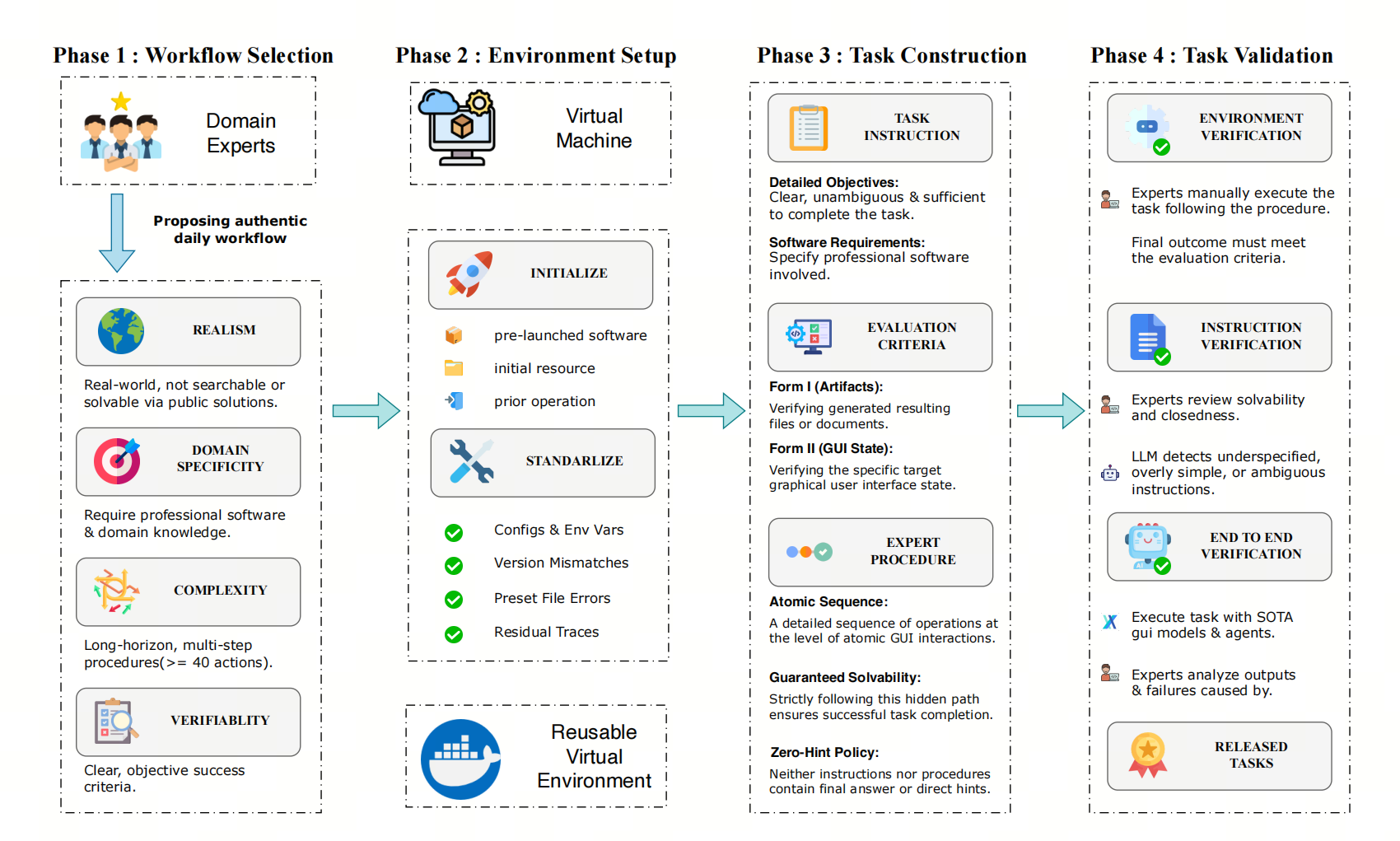
- Workflow-GYM is a benchmark designed to evaluate whether GUI agents can autonomously complete real-world professional workflows through graphical user interfaces.
- Unlike existing GUI benchmarks, which mainly focus on general-purpose applications and short tasks, Workflow-GYM covers 300 long-horizon tasks spanning 50+ specialized software tools across multiple domains.
- Our evaluation of SOTA models reveals that professional software workflows remain a major challenge: even the strongest models achieve only around 30% success rates. Through extensive analysis, we identify several key bottlenecks, including complex interface manipulation, long-horizon planning, professional software knowledge etc..
- Workflow-GYM provides a realistic testbed for studying the next generation of AI agents capable of performing economically valuable work in professional software environments.
—
▶—
Loading replay…
0 / 0
0%
Speed